

1. Introduction▲
Une expression régulière (ou expression rationnelle) est une chaîne de caractères permettant de décrire un ensemble de chaînes de caractères possibles.
Les expressions régulières permettent de trouver, extraire et même remplacer des éléments à l'intérieur d'une chaîne de caractères de manière très puissante.
Par exemple, si vous voulez contrôler la validité d'une adresse e-mail, il faut vérifier par exemple qu'il n'y a que des caractères alphanumériques, des tirets ou le caractère underscore, puis l'arobase devant le nom de domaine et un point devant l'extension, ... A première vue, c'est complexe à mettre en œuvre avec les outils standards qui nous permettent de manipuler les chaînes de caractères. Avec une expression régulière ça devient plus facile.
Dans ce document les expressions régulières sont en rouge, les chaînes traitées ou des extraits de celles-ci en vert et les correspondances en bleu.
2. Fonctionnement des expressions régulières▲
2-1. Une question d'automates▲
Les moteurs de traitement d'expressions régulières reposent sur l'utilisation d'automates finis, encore appelés machines à états finis.
On distingue 2 types de moteurs, ceux orientés texte et ceux orientés expression régulière (text-directed et regex-directed engines). Les premiers utilisent les automates finis déterministes (Deterministic Finite Automaton ou DFA), alors que les seconds utilisent les automates finis non déterministes (Nondeterministic Finite Automaton ou NFA).
Pour savoir à quel type de moteur on a affaire, il suffit de tester l'expression régulière beau|beaucoup avec la chaîne beaucoup. Un moteur orienté expression régulière renvoie beau, alors qu'un moteur orienté texte renverra beaucoup.
La différence est que les moteurs orientés expression régulière arrêtent la recherche dès qu'une correspondance valide a été trouvée. On dit que ces moteurs sont eager, que l'on pourrait traduire par pressé ou impatient.
Il faut également savoir que seuls les moteurs orientés expressions régulières permettent l'utilisation de ce que l'on appelle les backreference et les lazy quantifiers (ces deux points seront abordés plus loin dans ce guide). Ces moteurs sont généralement plus courants car les fonctionnalités citées précédemment sont plutôt pratiques.
Voyons maintenant à quoi correspondent ces automates finis.
2-1-1. Automate fini déterministe (DFA)▲
L'automate est utilisé pour traiter des mots, un mot étant un ensemble de symboles de l'alphabet de l'automate. Par exemple l'alphabet {a,b} constitué des symboles a et b permet la création des mots a, b, ab, aababb, ...
Un automate possède plusieurs états. Parmi ceux-ci on retrouve un état de départ et un ou plusieurs états finaux. Des transitions permettent de passer d'un état à un autre.
Un automate peut se représenter sous la forme d'un graphe. Par exemple, l'automate suivant correspond à l'expression [ab]*b ce qui permet de valider les mots de l'alphabet {a,b} se terminant par b.
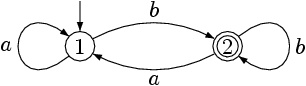
Chaque cercle correspond à un état. L'automate de l'exemple possède 2 états. L'état initial (ici l'état 1) est pointé par une flèche entrante, tandis que le ou les états finaux (ici l'état 2) sont représentés par 2 cercles.
On passe d'un état à un autre via une transition (représentée par une flèche allant d'un état à un autre). Une transition est associée à un symbole. Dans l'exemple, pour passer de l'état 1 à l'état 2 il faut lire le symbole b dans le mot en entrée.
Le mot en entrée sera validé si l'automate arrive dans un état final. Sinon le mot sera rejeté.
Un automate peut être également représenté par une table de transition qui décrit les différentes transitions entre les nœuds du graphe.
| a | b | |
| ->1 | 1 | 2 |
| *2 | 1 | 2 |
2-1-2. Automate fini non déterministe (NFA)▲
Un automate fini non déterministe est un automate tel que dans un état donné, il peut y avoir plusieurs transitions avec le même symbole. Le fonctionnement d'un tel automate n'est donc pas totalement "déterminé" car on ne sait pas quel état l'automate va choisir.
Voici un exemple d'automate fini non déterministe. Il correspond à l'expression [ab]*bab ce qui permet de valider les mots se terminant par bab.
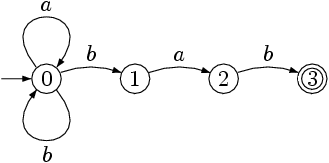
On constate en effet que l'on peut passer de l'état 0 à l'état 0 ou 1 lors de la lecture du symbole b. L'automate est donc non déterministe.
Il est possible de transformer un automate non déterministe en automate déterministe. Pour cela, il faut construire un nouvel état pour chaque sous-état atteignable. Pour comparaison, voici à quoi correspondrait l'automate précédent sous sa forme déterministe.
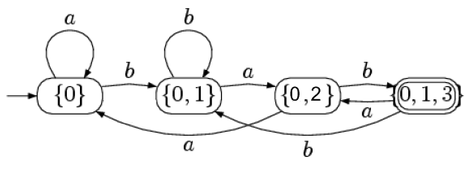
2-1-3. Automates à pile▲
Les automates à pile (Push Down Automaton ou PDA) sont une extension des automates précédents. Ce type d'automate gère des piles qu'il utilise pour stocker des informations. Nous verrons par la suite l'utilité de ces piles.
2-2. Moteur orienté expression régulière : un exemple▲
C'est volontairement que l'on se limitera aux moteurs orientés expression régulière. D'une part, ils sont plus courants et d'autre part c'est ce type de moteur que l'on retrouve sous .NET.
Comme dit plus haut, retenez bien qu'un moteur orienté expression régulière est eager, il retourne la première correspondance trouvée en allant de la gauche vers la droite (comportement par défaut, les moteurs possédant généralement une option pour pouvoir parcourir de la droite vers la gauche).
Le principe de base est que le moteur va lire un à un les caractères de la chaîne d'entrée (on consomme les caractères) et les confronter avec l'expression régulière. Pour faire le parallèle avec les automates, le moteur va donc lire un symbole en entrée et changer d'état en fonction de ce symbole. On avance donc à la fois dans la chaîne d'entrée et dans l'expression régulière, au fil des changements d'état de l'automate.
Nous allons maintenant voir un exemple pas à pas afin de vous aider à comprendre comment fonctionne un tel moteur. L'exemple est volontairement simpliste en utilisant uniquement des littéraux pour l'expression régulière. Le plus important est de bien voir comment procède le moteur. Cela vous aidera pour comprendre certains des exemples que nous verrons par la suite.
Pour cela nous allons appliquer l'expression régulière air à la chaîne Ce niais de maire ne manque pas d'air.
Dans un premier temps, le moteur va essayer de faire correspondre le premier caractère de la chaîne C avec le premier symbole de l'expression a. Ce qui échoue. Le moteur va donc ensuite avancer dans la chaîne et essayer de faire correspondre le e au a. Toujours un échec. Il en va de même pour l'espace, le n et le i qui suivent.
Le moteur va donc maintenant essayer de faire correspondre le a avec le a. Le moteur obtient une correspondance au 6ème caractère. On va alors avancer dans l'expression et dans la chaîne de caractères. Le moteur va ainsi tenter de faire correspondre le i avec le i. C'est une réussite. Malheureusement, le moteur va ensuite échouer sur la correspondance du s avec le r.
Le moteur ne trouvant pas de correspondance à partir du 6ème caractère va revenir en arrière pour recommencer son travail à partir du 7ème caractère. On appelle cela le backtracking. Il va alors essayer de faire correspondre le i avec le a. Et ainsi de suite jusqu'au 14ème caractère.
A ce stade, le a correspond au a, le i au i et le r au r. Le moteur a trouvé la correspondance air avec l'expression au 14ème caractère. Il va donc renvoyer ce résultat.
Il faut savoir que les outils manipulant les expressions régulières sont généralement capables de renvoyer l'ensemble des correspondances et non uniquement la première. Pour cela le moteur avance dans la chaîne pour se positionner après la dernière correspondance et il recommence à traiter l'expression régulière depuis cette position.
Dans la suite de ce document, les correspondances seront données comme le ferait le logiciel gratuit Expresso (designer d'expression régulière). C'est-à-dire qu'on se ne limitera pas à la première correspondance trouvée.
3. Syntaxe des expressions régulières▲
L'écriture d'une expression régulière se base sur l'utilisation de littéraux et de métacaractères. L'ensemble de ces littéraux et métacaractères forme ce que l'on appelle alors une expression régulière. On utilise également le terme de pattern pour qualifier cet ensemble, ou encore regex et regexp.
3-1. Les littéraux▲
Les littéraux sont des symboles qui vont être interprétés tels qu'ils sont écrits. Par exemple si on prend le littéral a appliqué à la chaîne Salut, on aura comme résultat le a qui se trouve après le caractère S. De la même façon, beau trouvera beau dans la chaîne Il fait beaucoup d'efforts.
Les expressions régulières sont par défaut sensibles à la casse (case sensitive) il faut donc faire attention. Ce comportement peut néanmoins être modifié, les moteurs possédant généralement une option dans ce but.
3-2. Les métacaractères▲
Les métacaractères sont des caractères spéciaux ayant une signification particulière dans l'expression régulière. Ils nous permettent de réaliser des expressions plus complexes lorsque les littéraux seuls ne sont d'aucune aide. Ce qui est en général toujours le cas.
| Métacaractère | Description |
| [ | Définition d'une classe de caractères |
| \ | Caractère d'échappement |
| ^ | Négation ou début de ligne |
| $ | Fin de ligne |
| . | N'importe quel caractère sauf la fin de ligne |
| | | Opérateur OU |
| ? | Répète zéro ou une fois |
| * | Répète autant de fois que voulu (zéro ou plus) |
| + | Répète une fois ou plus |
| ( et ) | Définition d'un groupe |
Il est possible d'utiliser ces caractères en tant que littéraux, il faut alors les échapper avec le caractère \.
3-3. Les classes de caractères▲
Les classes (ou jeux) de caractères permettent de définir un ensemble de caractères, sachant qu'un seul caractère de l'ensemble pourra être utilisé dans la correspondance.
3-3-1. Définition d'une classe de caractères▲
On crée une classe de caractères en mettant les caractères à rechercher entre crochets.
Par exemple, si l'on veut indiquer qu'un caractère doit être une voyelle on peut utiliser l'expression [aeiouy]. Appliquée à la chaîne Salut, cette expression aura comme correspondance le a et le u.
3-3-2. Définition d'une plage de caractères▲
Il est possible de spécifier une plage de caractères en utilisant le tiret. Ainsi, l'expression [0-9] correspond à un caractère numérique (un caractère entre 0 et 9).
On peut spécifier plusieurs plages si besoin. [a-zA-Z] permet ainsi de trouver n'importe quelle lettre, minuscule ou majuscule.
3-3-3. Négation au sein d'une classe de caractères▲
Il est possible de définir une négation afin de dire que le caractère à trouver n'appartient pas à un ensemble de caractères donné. Pour cela on utilise le caractère ^ en le plaçant immédiatement après le crochet ouvrant.
Ainsi, si l'expression [0-9] permet d'effectuer une correspondance avec tout caractère numérique, [^0-9] indique une correspondance avec les caractères qui ne sont pas numériques.
3-3-4. Soustraction de classes de caractères▲
Il est possible de définir une classe de caractères par soustraction. Imaginons par exemple que l'on veuille une expression qui corresponde à une consonne. Il y a 2 solutions, soit on liste l'ensemble des consonnes soit on crée une classe par soustraction en indiquant que l'on veut toutes les lettres sauf les voyelles. La deuxième solution a l'avantage d'être plus simple car plus courte.
On définit une soustraction de classes avec une expression de la forme [A-[B]], où A représente la classe principale et B la classe à soustraire de A. Ainsi pour obtenir l'ensemble des consonnes on peut utiliser l'expression [a-z-[aeiouy]].
On définit la classe principale (la plage de caractères [a-z]) et la classe des caractères non souhaités (l'ensemble des voyelles [aeiouy]). La soustraction de ces deux classes donne au final l'ensemble des consonnes.
3-3-5. Métacaractères dans une classe de caractères▲
Les métacaractères sont considérés comme des littéraux au sein d'une classe de caractères. On peut donc les utiliser sans avoir à les échapper. Exception faite des caractères \, ], ^ et - qui devront être échappés (en les précédant d'un \).
Les caractères ], ^ et - ont un rôle particulier dans les classes de caractères. Il est alors possible de les utiliser sans avoir à les échapper en les positionnant de manière à ce qu'ils ne remplissent pas leurs rôles.
3-3-6. Raccourcis▲
Il existe des raccourcis pour les classes de caractères souvent utilisées.
| Raccourci | Description |
| \d | Représente un chiffre. Equivalent de [0-9] |
| \w | Représente un caractère de mot (mot dans le contexte expression régulière, ce qui n'a rien à voir avec la notion de mot dans le contexte de la langue française). Equivalent de [a-zA-Z0-9_] |
| \s | Représente un caractère d'espacement. Equivalent de [ \t\r\n] |
| \D | Représente un caractère qui n'est pas un chiffre (contraire de \d) |
| \W | Représente un caractère qui n'est pas un caractère de mot (contraire de \w) |
| \S | Représente un caractère qui ne soit pas d'espacement (contraire de \s) |
3-4. Les ancres▲
Les ancres sont des métacaractères un peu particuliers. Ils ne correspondent à aucun caractère. Ils servent à définir une position avant, après ou entre les caractères.
3-4-1. Début et fin de ligne▲
L'accent circonflexe ^ représente le début d'une ligne alors que le dollar $ représente la fin d'une ligne. Ainsi, l'expression ^s renverra le s au début de sexisme et e$ renverra le e se trouvant à la fin.
Le comportement par défaut de certains moteurs est de travailler sur une seule ligne (c'est le cas en .NET). A ce moment, ^ et $ représentent le début et la fin de la chaîne. Il faut explicitement indiquer que l'on travaille sur plusieurs lignes pour que ^ et $ représente le début et la fin de chaque ligne.
Par exemple, si l'on prend l'expression ^. et la chaîne :
Il fait
très beau
ce matin
Si ^ représente le début de la chaîne alors la seule correspondance trouvée sera le I du début. Par contre si ^ représente le début de la ligne, alors il y a aura trois correspondances : I, t et c.
3-4-2. Word boundaries▲
Le métacaractère \b représente une position que l'on appelle "word boundary".
Les positions correspondant à cette ancre sont les suivantes :
- avant le premier caractère de la chaîne, si ce caractère est un caractère de mot
- après le dernier caractère de la chaîne, si ce caractère est un caractère de mot
- entre deux caractères de la chaîne, si l'un est un caractère de mot et l'autre non
Cela permet de faire une recherche de mots avec une expression de la forme \bLeMot\b.
Par exemple, l'expression \bchien\b appliquée à un chien et une chienne capturera le chien après un et c'est tout.
Le métacaractère \B est le contraire de \b, il représente donc les positions ne correspondant pas à celles de \b.
3-5. Les alternatives▲
Il est possible d'indiquer des alternatives avec l'opérateur OU. Ainsi, si l'on veut chercher les textes chat ou chien il suffit de les séparer par le caractère | ce qui donne l'expression chat|chien. Le nombre d'options n'est pas limité, il suffit de compléter la liste : chat|chien|poisson|...
L'opérateur OU est le moins prioritaire dans les expressions régulières, il faudra donc grouper l'ensemble si nécessaire. Par exemple pour une recherche de mot il faudrait utiliser \b(chat|chien|poisson)\b.
Les différentes alternatives sont évaluées de la gauche vers la droite. Si une alternative échoue, le moteur pourra revenir en arrière (backtracking) pour essayer l'alternative suivante.
3-6. Les répétitions▲
Les répétitions vont permettre d'indiquer qu'il faut répéter un certain nombre de fois le symbole précédent dans l'expression régulière.
| Répétition | Description |
| * | Répète autant de fois que voulu (zéro ou plus) |
| + | Répète une fois ou plus |
| ? | Répète zéro ou une fois (représente donc un item optionnel) |
| {n} | Répète n fois exactement |
| {n,} | Répète au moins n fois |
| {n, m} | Répète au moins n fois mais pas plus de m |
Ainsi \d+ permettra de trouver 1 et 23 dans la chaîne tango1 et charlie23 tandis que \b\w+\b permettra de capturer tous les "mots" d'une chaîne.
Par défaut, le comportement des expressions régulières est de rechercher la chaîne la plus longue possible : les expressions régulières sont dites greedy, que l'on pourrait traduire par gloutonne. Nous allons voir la conséquence de ce comportement en regardant comment le moteur procède dans le traitement d'une expression avec des répétitions.
Pour cela nous allons prendre l'expression <.+> et la chaîne Voici un <h1>titre</h1> en HTML.
Le moteur va donc traiter la chaîne jusqu'à arriver sur le premier < qui correspond au début de la balise <h1> de notre expression. Le prochain symbole est le point, qui représente n'importe quel caractère. Ce point est répété une ou plusieurs fois.
Le moteur va donc continuer à avancer dans la chaîne validant ainsi le h, le 1, ... jusqu'à avoir <h1>titre</h1> en HTML, car le moteur prend le plus de caractères possible. A ce stade, on se trouve au bout de la chaîne et il est évident que > va échouer.
Le moteur va alors revenir en arrière (toujours le backtracking) et recommencer l'opération, mais cette fois-ci en diminuant la répétition de 1, afin d'obtenir <h1>titre</h1> en HTM. Le moteur échouera ensuite avec >. On recommence encore et encore jusqu'à arriver à <h1>titre</h1. Maintenant le > va correspondre au >, le moteur donnera donc une correspondance avec <h1>titre</h1>.
3-6-1. Répétitions au plus court▲
Par défaut, les expressions régulières sont greedy. Il est néanmoins possible de modifier ce comportement en demandant une recherche au plus court.
| Répétiton | Description |
| *? | Répète autant de fois que voulu, avec le plus petit nombre de caractères |
| +? | Répète une fois ou plus, avec le plus petit nombre de caractères |
| ?? | Répète zéro ou une fois, avec le plus petit nombre de caractères |
| {n,}? | Répète au moins n fois, avec le plus petit nombre de caractères |
| {n, m}? | Répète au moins n fois mais pas plus de m, avec le plus petit nombre de caractères |
Ces opérateurs sont qualifiés de lazy quantifiers (quantifieurs paresseux).
Par exemple, l'expression a.*b aura comme correspondance aabab avec la chaîne aabab.
Par contre avec a.*?b la correspondance sera aab et ab dans la même chaîne. L'utilisation d'une répétition au plus court permet donc de modifier le comportement greedy en demandant le moins de caractères possible.
Voyons encore une fois comment le moteur traite les répétitions au plus court. Pour cela nous prendrons l'expression <.+?> et la chaîne Voici un <h1>titre</h1> en HTML.
Le moteur va donc traiter la chaîne jusqu'à arriver sur le premier < qui correspond au < de notre expression. Le prochain symbole est le point, qui représente n'importe quel caractère. Ce point est répété une ou plusieurs fois, avec le moins de répétitions possible.
Ici, la répétition minimum est de 1 caractère. Le point répété va donc correspondre au h. Le moteur continue l'évaluation en faisant correspondre le > avec le 1. Cela échoue. Le moteur revient en arrière (backtracking toujours) et va augmenter la répétition de 1. Le point répété va ainsi correspondre à h1. Ensuite > correspondra bien au >. Le moteur retourne donc <h1>. En continuant, </h1> correspond aussi à l'expression.
On peut souvent utiliser une classe de caractères pour réaliser la même opération. Ainsi l'expression <[^>]+> donnera le même résultat, sans avoir besoin de faire du backtracking.
3-7. Les groupes▲
Il est possible de créer des sous-expressions avec les groupes. Pour créer un groupe, il faut entourer l'expression par des parenthèses. Ainsi, (\d{1,3}\.){3}\d{1,3} est une expression simplifiée permettant de représenter une adresse IP.
Créer un groupe crée également ce que l'on appelle une backreference, c'est-à-dire qu'il sera possible de référencer le groupe pour réutiliser la dernière valeur qu'il aura capturée.
Par exemple, l'expression <(.*)>.*</\1> permet de valider une chaîne comme <balise>du texte</balise>. Ici \1 est une backreference sur le groupe 1. Attention néanmoins, une backreference vers un groupe n'ayant rien capturé échouera toujours lors de l'évaluation de l'expression. Ainsi l'expression (a)?b\1c n'aura aucune correspondance avec bc.
S'il n'y a pas besoin d'avoir une backreference ou que l'on ne veut pas capturer le groupe, il est possible de l'indiquer. Si l'on reprend l'exemple de l'adresse IP, l'expression (?:\d{1,3}\.){3}\d{1,3} utilise un groupe, mais il ne sera pas capturé et il n'y aura donc pas de backreference créée.
| Groupement | Description |
| () | Sert à définir un groupe (les groupes sont numérotés à partir de 1) |
| (?:) | Sert à définir un groupe qui ne sera pas capturé (non capturing group) |
| \i | Référence le groupe qui a pour index i |
Certains langages, comme .NET, permettent l'utilisation de forwardreference, c'est-à-dire que l'on peut référencer un groupe qui est défini plus loin dans l'expression.
3-7-1. Groupes nommés▲
Par défaut, les groupes sont numérotés dans l'ordre d'apparition (l'index démarre à 1). Mais il est possible de nommer les groupes.
| Groupement | Description |
| (?<name>) | Sert à définir un groupe nommé |
| \k<name> | Référence le groupe qui a pour nom name |
En .NET, les groupes nommés sont également accessibles par leur index, mais ils sont numérotés après les groupes non nommés.
3-7-2. Backreference et répétitions▲
Si un groupe est capturé plusieurs fois, la backreference prendra la dernière valeur du groupe. Prenons par exemple (\d+) et (\d)+. Les deux expressions semblent similaires mais leur comportement est totalement différent pour ce qui est des backreference.
Les deux expressions correspondent à 123, mais si avec la première la backreference contient 123, pour la seconde la backreference contiendra 3.
La différence vient du fait que l'on capture plusieurs caractères avec la première expression, alors que l'on répète la capture d'un caractère avec la deuxième.
3-8. Lookaround▲
Les lookaround (fonctions de préanalyse et de postanalyse positives et négatives) peuvent être assimilés aux ancres si l'on considère le fait que cela va permettre de définir une position.
Contrairement aux ancres, les lookaround vont essayer de trouver une correspondance par rapport à une expression, mais sans consommer de caractères. Cela va nous permettre de définir des positions par rapport à une condition.
3-8-1. Positive et negative lookahead (préanalyse)▲
L'expression \d+(?=€) utilise ce que l'on appelle un positive lookahead. Cette expression permet de trouver les suites de chiffres qui sont suivies par un €, le € ne faisant pas partie de la correspondance. On pourrait traduire (?=expression) par, "est-ce que expression se trouve après cette position ?".
Le negative lookahead c'est l'inverse. Ainsi \d+(?!€) permet de trouver les suites de chiffres qui ne sont pas suivies par un €. On pourrait traduire (?!expression) par, "est-ce que expression ne se trouve pas après cette position ?".
Le negative lookahead est indispensable si l'on veut trouver quelque chose qui n'est pas suivi par autre chose.
3-8-2. Positive et negative lookbehind (postanalyse)▲
C'est le même principe que ci-dessus, mais dans le sens inverse. Au lieu de demander au moteur de regarder après, on va lui demander de revenir en arrière pour vérifier si l'assertion du lookbehind peut être vérifiée.
Ainsi l'expression (?<=\d+)€, à base de positive lookbehind, permet de trouver les € qui sont précédés par une suite de chiffres. On pourrait donc traduire (?<=expression) par, "est-ce que expression se trouve avant cette position ?".
Avec le negative lookbehind, (?<!\d+)€, on recherche au contraire les € qui ne sont pas précédés par une suite de chiffres. On pourrait donc traduire (?<!expression) par, "est-ce que expression ne se trouve pas avant cette position ?".
3-8-3. Exemples d'utilisation▲
Une des utilisations des lookahead et lookbehind peut être l'extraction de données entre des balises. Si on prend la chaîne <lien>Le texte > de mon < lien</lien><lien>Un > autre < lien</lien>, on peut extraire le contenu entre les balises avec l'expression (?<=<lien>).+?(?=</lien>). Ce qui donnera Le texte >de mon< lien et Un >autre< lien.
Une autre utilisation classique est la validation de mot passe si, par exemple, vous devez imposer qu'un mot de passe possède entre 6 et 10 caractères, avec la présence d'au moins un chiffre, une lettre minuscule et majuscule et un caractère spécial. L'expression ^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[!_?*-]).{6,10}$ permet de répondre à ce besoin.
L'utilisation d'un positive lookahead nous permet de tester dans un premier temps si l'on se trouve devant zéro ou plusieurs caractères suivis d'un chiffre. Ensuite, on teste si la chaîne qui suit le lookahead contient une minuscule, une majuscule et un caractère spécial. Pour finir, il ne reste plus qu'à tester s'il y a bien entre 6 et 10 caractères.
On se rend vite compte que les lookaround permettent de réaliser des expressions qui auraient été impossibles à réaliser sans, ou qui s'en trouveraient bien plus compliquées.
3-9. Condition dans une expression régulière▲
Il est possible d'inclure des conditions dans une expression régulière. La syntaxe d'une condition est la suivante (?(expression)alors|sinon). Si l'expression est valide la clause alors sera évaluée, autrement ce sera la clause sinon. La clause sinon étant facultative.
Pour l'expression de test, on utilise soit un lookaround soit une backreference sur un groupe (en utilisant le numéro ou le nom du groupe comme expression). Dans le cas du groupe, s'il est vide (pas de capture) alors l'expression est fausse.
Par exemple, l'expression (?(?<=a)b|c) permet de valider le b de ab ou bien le c de dc.
3-10. Balancing groups▲
3-10-1. Une histoire de pile▲
Comme nous l'avons vu précédemment, les groupes permettent de capturer une occurrence dans la chaîne. Si un même groupe réalise plusieurs captures, ces différentes captures sont conservées dans une pile. La backreference renvoie la valeur présente sur le haut de la pile, sans la retirer.
Un groupe correspond donc à une pile qui contient l'ensemble des captures du groupe, ainsi que leurs positions. Si l'on prend l'expression (\w)+ appliquée à ab, le groupe 1 contiendra deux valeurs dans la pile : b et a.
La notion de balancing groups fait appel à ces piles afin de permettre des traitements puissants. Un exemple classique consiste par exemple à vérifier que dans une chaîne les parenthèses sont bien imbriquées.
Les expressions utiles seront les suivantes.
| Expression | Description |
| (?<Name1>expression) | Définition d'un groupe nommé. La valeur capturée est mise sur la pile Name1. |
| (?<-Name1>expression) | Retire la dernière capture de la pile. Si la pile était vide l'expression échoue |
| (?<Name2-Name1>expression) | Retire la dernière capture de la pile Name1 et met sur la pile Name2 le texte compris entre la position de la dernière capture et la position courante |
| (?(Name1)(?!)) | Permet de tester si la pile Name1 est vide en utilisant un negative lookahead sans expression (?!), ce dernier échouant toujours si la pile n'est pas vide |
3-10-2. Un premier exemple : la recherche de palindrome▲
Un palindrome est un mot ou un texte que l'on peut lire de gauche à droite ou de droite à gauche sans que l'ordre des lettres change. Par exemple "Laval" ou "Elu par cette crapule". Les caractères diacritiques (accents, cédilles, ...) ne sont généralement pas pris en compte, de même que les caractères d'espacement, ponctuation, ... dans le cadre d'un texte.
Voici l'expression que nous utiliserons pour la recherche : (?<C>.)+.?(?<-C>\k<C>)+(?(C)(?!))
Nous utiliserons la chaîne Laval pour tester cette expression. La casse ne sera pas prise en compte dans l'évaluation.
Le moteur va commencer par évaluer le L avec (?<C>.). Cela correspond. On va donc empiler le L, qui se trouve à la position 1, sur la pile C. L'opération est répétée une ou plusieurs fois. Le moteur va donc prendre le plus de caractères possible, jusqu'à lire tous les caractères (la pile contient alors l, a, v, a et L). Le moteur effectue alors le backtracking car le reste de l'expression échoue à ce stade. On revient donc en arrière, la pile est également rétablie et contient de nouveau le L.
Le moteur continue ainsi les évaluations et les backtracking jusqu'à valider La, la pile contient alors a et L. Le v correspond ensuite au .? (cela permet de tenir compte des palindromes "impairs"). Ensuite, le moteur teste le a avec (?<-C>\k<C>). \k<C> correspond à la dernière capture du groupe nommé C (la valeur en haut de la pile C donc).
Evidemment, a correspond bien au a qui se trouve en haut de la pile C. L'évaluation ayant réussi, on dépile la valeur. La pile contient maintenant le L. Le moteur va donc évaluer le l avec le L de la pile ce qui correspond. On dépile la valeur, laissant une pile vide. Reste maintenant à évaluer (?(C)(?!)). La pile étant vide l'expression est validée, et Laval ressort comme étant un palindrome.
En schématisant :
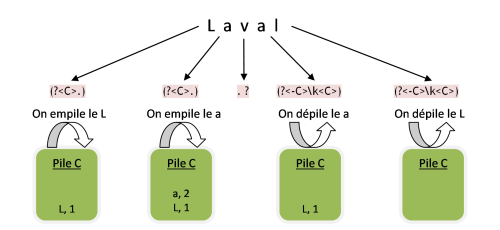
3-10-3. Un second exemple : imbrication des parenthèses▲
Nous allons maintenant voir l'exemple classique de l'utilisation des balancing groups, à savoir l'imbrication des parenthèses (ou tout autre délimiteur comme les guillemets). Nous utiliserons l'expression suivante :
\(
(?>
[^()]+
|
(?<P>)\(
|
(?<-P>)\)
)*
(?(P)(?!))
\)
Le principe est le même qu'avec la recherche de palindrome, nous ne détaillerons donc pas le processus.
Par contre, avec une petite variante il sera possible de capturer les différents blocs entre les parenthèses. L'expression devient la suivante :
\(
(?>
[^()]+
|
\((?<P>)
|
(?<C-P>)\)
)*
(?(P)(?!))
\)
Lorsque l'on rencontre une parenthèse fermante on va ainsi mettre sur la pile C le texte compris entre la position courante et la position de la dernière capture qui se trouve sur la pile P. Cela permet au final de capturer le texte qui se trouve entre parenthèses.
Voici un schéma pour synthétiser ce dernier cas :
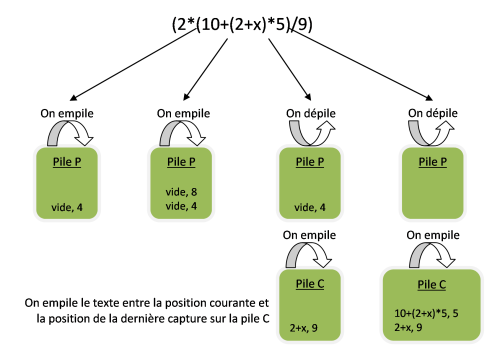
3-11. Les substitutions▲
Les expressions régulières peuvent être utilisées pour faire du remplacement dans les chaînes de caractères. A cette fin, il existe des motifs de substitutions qui peuvent être utilisés dans la définition de la chaîne de remplacement.
| Substitution | Description |
| $i | Valeur du groupe qui a pour index i |
| ${name} | Valeur du groupe qui a pour nom name |
| $& | Texte de l'occurrence trouvée |
| $` | Texte précédant l'occurrence trouvée |
| $' | Texte suivant l'occurrence trouvée |
Par exemple, si l'on prend la chaîne Roger Dupont et l'expression régulière (\w+)\s+(\w+), le groupe 1 contiendra Roger et le groupe 2 Dupont. En utilisant comme chaîne de remplacement $2 $1, on obtiendra après remplacement la chaîne Dupont Roger.
3-12. Expressions régulières et caractères accentués▲
Dans une langue comme le français, il y a des caractères accentués (à, é, ç, ...). Il faut prendre quelques précautions lorsque ces caractères entrent en jeu et que vous ne pouvez pas vous permettre de nettoyer la chaîne pour retirer les accents avant de la manipuler.
Ainsi, l'expression [a-z] ne permet pas de capturer un caractère accentué. L'expression \w le permet, mais elle peut éventuellement capturer trop d'informations (chiffre, underscore).
\w permet de valider également les ligatures (æ, œ, ...) et les lettres d'autres langues (par exemple ß ou µ). De la même façon, \d correspond à un caractère associé à un chiffre, et ce, indépendamment de la culture.
Une possibilité est d'utiliser une classe de caractères avec une soustraction, par exemple l'expression [\w-[0-9_]]. Une autre possibilité est l'utilisation des classes de caractères basées sur Unicode. On peut citer par exemple les classes \p{L}, \p{Ll} et \p{Lu}.
| Unicode | Description |
| \p{L} | Représente une lettre de n'importe quel langues |
| \p{Ll} | Représente une lettre minuscule possédant une variante majuscule |
| \p{Lu} | Représente une lettre majuscule possédant une variante minuscule |
4. Les expressions régulières avec .NET▲
4-1. Classe System.Text.RegularExpressions.Regex▲
La classe System.Text.RegularExpressions.Regex est le point d'entrée pour tous les traitements à base d'expressions régulières.
Cette classe propose 5 méthodes principales. Il existe une surcharge statique pour chacune d'elle, il n'est donc pas nécessaire d'instancier un objet de type Regex.
4-2. Méthode Regex.IsMatch▲
Cette méthode indique s'il existe une correspondance dans la chaîne d'entrée à l'aide de l'expression régulière spécifiée. C'est la méthode classique à utiliser pour valider une saisie utilisateur.
Imaginons que l'on demande à l'utilisateur de saisir une adresse IP par exemple. Afin de vérifier que la saisie semble correcte, on va la confronter avec une expression régulière qui permettra de valider que le texte correspond à une IP.
bool valid = Regex.IsMatch("192.168.10.1", @"^(\d{1,3}\.){3}\d{1,3}$");Lors de la validation d'une saisie on veut vérifier l'intégralité de la chaîne d'entrée, l'expression régulière commence donc généralement par ^ et fini par $.
L'exemple précédent n'est pas tout à fait correct, car dans une adresse IP chaque plage est comprise entre 0 et 255. Il faudrait donc utiliser une expression plus complète telle que :
((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)Un autre exemple dont nous parlions en introduction, est la validation d'une saisie d'adresse email. Voici une expression parmi d'autres, car l'expression dépend avant tout du contexte dans lequel elle est utilisée, pour le faire :
bool valid = Regex.IsMatch("monEmail@fai.com", @"^[A-Z0-9.]+@[A-Z0-9.-]+\.[A-Z]{2,4}$");4-3. Méthode Regex.Match▲
Cette méthode recherche dans la chaîne d'entrée une occurrence de l'expression régulière spécifiée. Cette méthode permet donc de chercher du texte et d'extraire la première occurrence trouvée.
string input = "AZ-132BF/2009";
Match match = Regex.Match(input, @"^([A-Z]{2})-(\d{3}[A-Z]{2})/(\d{4})$");Ici, nous utilisons la méthode Match pour réaliser deux fonctions à la fois.
Premièrement, parce que l'expression régulière commence par ^ et fini par $, nous cherchons à avoir une correspondance avec la chaîne d'entrée en entier. Comme on le ferait avec la méthode IsMatch.
Afin de savoir si la chaîne correspond, il suffit ensuite d'un simple test :
if (match.Success)
{
// L'entrée correspond à l'expression régulière.
}Deuxièmement, l'utilisation des groupes va nous permettre de récupérer les informations de la chaîne avec l'objet Match.
if (match.Success)
{
string s1 = match.Groups[1].Value; // Capture AZ
string s2 = match.Groups[2].Value; // Capture 132BF
string s3 = match.Groups[3].Value; // Capture 2009
}La propriété Match.Groups va permettre d'accéder aux différents groupes capturés par l'expression régulière. Ici on utilise l'index du groupe, mais on peut également utiliser une chaîne lorsqu'on a des groupes nommés.
Les index de groupe commencent à 1 pour les expressions régulières, l'index 0 est utilisé pour la valeur du match. match.Groups[0].Value correspond donc à match.Value.
4-4. Méthode Regex.Matches▲
Cette méthode est une extension de Regex.Match, elle permet de récupérer toutes les occurrences trouvées.
string input = "AZ-132BF/2009;CR-760AA/2009;XX-005ET/2008";
MatchCollection matches = Regex.Matches(input, @"\b([A-Z]{2})-(\d{3}[A-Z]{2})/(\d{4})\b");
foreach (Match match in matches)
{
string s1 = match.Groups[1].Value;
string s2 = match.Groups[2].Value;
string s3 = match.Groups[3].Value;
}4-5. Méthode Regex.Replace▲
Cette méthode va permettre de remplacer dans la chaîne d'entrée toutes les chaînes qui correspondent à l'expression régulière spécifiée par une chaîne de remplacement.
Imaginons que nous ayons un fichier texte avec les noms des différents employés d'une société. A partir de ce fichier, on veut créer une liste d'adresse email de manière automatique. Pour l'exemple on suppose que les noms/prénoms ne sont pas composés.
string input = "Roger Dupont;Paul Ricard;Alice Presto";
string output = Regex.Replace(input.ToLower(),
@"(\w)\w+\s+(\w+);?",
"$1$2@domaine.com\r\n");On aura ainsi comme résultat la chaîne suivante :
rdupont@domaine.com
pricard@domaine.com
apresto@domaine.comIl existe une surcharge de la méthode prenant en argument un délégué de type MatchEvaluator au lieu d'une chaîne de remplacement. Cela permet ainsi des traitements plus complexes.
Reprenons l'exemple des balises avec les lookaround. La chaîne <lien>Le texte > de mon < lien</lien> n'est pas valide du point de vue XML car les < et > entre les balises viennent nous gêner. Il serait impossible de charger un fichier XML avec ce type de contenu. Si l'on imagine maintenant que le texte entre les balises doit être compatible HTML, il n'y a pas que les < et > qui peuvent être gênants.
Il est évident qu'on ne peut pas spécifier une chaîne de remplacement comme dans l'exemple précédent. La solution c'est d'utiliser la surcharge avec MatchEvaluator.
string input = " <lien>Le texte > de mon < lien</lien> ";
input = Regex.Replace(input, "(?<=<lien>).+?(?=</lien>)",
delegate(Match m)
{
return System.Web.HttpUtility.HtmlEncode(m.Value);
});On obtiendra ainsi la chaîne :
<lien>Le texte > de mon < lien</lien>On voit rapidement que cette méthode permet de faire des choses assez intéressantes. Prenons un autre exemple.
Imaginons que l'utilisateur doit saisir des références notées sur papier : les références commencent par dix lettres et finissent par cinq chiffres. Malheureusement l'utilisateur est nouveau et ne le sait pas, il peut donc faire des erreurs de saisies si la référence est mal écrite. Par exemple un I au lieu d'un 1 et inversement. Les caractères litigieux sont ainsi le 1 et le I, le 2 et le Z, le 5 et le S, le 8 et le B, le 0 et le O.
L'utilisateur va donc par exemple saisir 5TDOP1AFG096SO0 alors que STDOPIAFGO96500 était attendu. On va maintenant utiliser la méthode Replace avec une expression régulière pour corriger automatiquement la saisie.
L'idée est de rechercher tous les chiffres qui se trouvent dans les dix premiers caractères (c'est-à-dire les chiffres suivis par au moins cinq caractères) et toutes les lettres dans les cinq derniers caractères (c'est-à-dire les lettres précédées par au moins dix caractères). Pour chaque caractère capturé, il faudra ensuite renvoyer son équivalent en chiffre / lettre suivant les cas.
Notre expression serait donc la suivante [12580](?=.{5,})|(?<=.{10,})[IZSBO] et le code :
string input = "5TDOP1AFG096SO0";
string regex = "[12580](?=.{5,})|(?<=.{10,})[IZSBO]";
input = Regex.Replace(input, regex,
delegate(Match m)
{
switch (m.Value)
{
case "1" :
return "I";
case "I" :
return "1";
case "2" :
return "Z";
case "Z" :
return "2";
...
case "0" :
return "O";
case "O" :
return "0";
}
});Une fois traitée, la chaîne d'entrée sera alors corrigée en STDOPIAFGO96500.
4-6. Méthode Regex.Split▲
Cette méthode permet de découper une chaîne de caractères, comme la méthode String.Split, à la différence que le critère de découpage est une expression régulière.
Une particularité de cette méthode est qu'il est possible d'avoir dans le tableau de sortie les délimiteurs, à condition d'avoir défini un groupe dans l'expression régulière.
Par exemple, avec ce code :
string[] chaines = Regex.Split("chien-chat/poisson", "(-)|(/)");Le tableau résultat contiendra les chaînes "chien", "-", "chat", "/" et "poisson".
Si maintenant on retire les parenthèses :
string[] chaines = Regex.Split("chien-chat/poisson", "-|/");Le tableau résultat contiendra alors "chien", "chat" et "poisson".
4-7. Les options▲
L'énumération RegexOptions permet de définir des options pour le traitement de l'expression régulière.
Parmi ces options on trouve par exemple les options IgnoreCase, pour ne pas tenir compte de la casse, et MultiLine, pour modifier le comportement des ancres ^ et $ (début et fin de la chaîne ou de chaque ligne). On peut également citer les options ExplicitCapture, qui force à déclarer clairement dans l'expression les groupes que l'on veut capturer évitant ainsi la capture de groupes inutiles, et Compiled, qui peut améliorer les performances lorsqu'une expression est utilisée de manière intensive.
Cette énumération possède un attribut FlagsAttribute qui permet la combinaison d'opérations de bits de ses valeurs de membres.
4-8. Accès aux différentes captures d'un groupe▲
Il est possible de consulter la pile d'un groupe (cf. chapitre 3.10). La propriété Captures d'un groupe contient les différentes captures associées au groupe. Si l'on reprend l'exemple du chapitre 3.10.1
Match m = Regex.Match("ab", @"(\w)+");Alors :
m.Groups[0].Value => ab // Correspondance de l'expression
m.Groups[1].Value => b // Dernière capture du groupe
m.Groups[1].Captures[0].Value => a // Première capture du groupe
m.Groups[1].Captures[1].Value => b // Seconde capture du groupeOn peut faire la même chose avec les groupes nommés. Modifions légèrement notre expression pour valider une adresse IP afin de pouvoir également extraire chaque valeur de l'adresse.
(?:(?<ip>25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?<ip>25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)Les différentes valeurs seront accessibles en passant par les différentes captures du groupe nommé ip. Si maintenant on applique cette expression à la chaîne 123.54.1.10 :
m.Groups[0].Value => 123.54.1.10
m.Groups["ip"].Value => 10
m.Groups["ip"].Captures[0].Value => 123
m.Groups["ip"].Captures[1].Value => 54
m.Groups["ip"].Captures[2].Value => 1
m.Groups["ip"].Captures[3].Value => 105. Conclusion▲
Ce guide est maintenant terminé. J'ai essayé de présenter les expressions régulières de manière assez complète en insistant sur le fonctionnement du moteur. Cela permet ainsi de mieux comprendre comment l'expression est évaluée et donc de mieux comprendre les résultats obtenus.
Si certains points ne sont pas clairs ou que vous avez des questions, n'hésitez pas à poster sur la discussion associée à cet article afin de m'aider à l'améliorer.
Remerciements▲
Je tiens ici à remercier l'équipe .NET de Developpez.com pour ses relectures attentives et ses suggestions, ainsi que Bérénice MAUREL, Wachter et ram-0000.